Code
from gingado.utils import load_SDMX_dataThis notebook illustrates the use of gingado to build models for forecasting, using foreign exchange (FX) rate movements as an example. Please note that the results or the model should not be taken as investment advice.
Forecasting exchange rates is notoriously difficult (Rossi (2013) and references therein).
This exercise will illustrate various functionalities provided by gingado:
how to use gingado utilities, such as an object to compare different lags of the model and a function that downloads specific SDMX data.
how to augment the original dataset of interest
how to quickly create a benchmark model, and use it compare different alternatives
how to document the model
Unlike most scripts that concentrate the package imports at the beginning, this walkthrough will import as needed, to better highlight where each contribution of gingado is used in the workflow.
First, we will use gingado to run a simple example with the following characteristics:
selected currency pairs will be downloaded from the European Central Bank (ECB) servers using the SDMX protocol
using gingado, this series will be augmented with a time series on central bank policy rates and the interaction of rate changes and FX rate movements
the regressors (including the FX rates themselves) are lagged up to 10 lags using the gingado utility Lag
a different benchmark model is created for each of the FX rates, using a random forest
gingado will automatically search for the best specification for each currency pair from a default list of hyperparametersthroughout the example, ModelCard is used to document the models being trained
In this exercise, we will concentrate on the bilateral FX rates between the 🇺🇸 US Dollar (USD) and the 🇧🇷 Brazilian Real (BRL), 🇨🇦 Canadian Dollar (CAD), 🇨🇭 Swiss Franc (CHF), 🇪🇺 Euro (EUR), 🇬🇧 British Pound (GBP), 🇯🇵 Japanese Yen (JPY) and 🇲🇽 Mexican Peso (MXN).
The rates are standardised to measure the units in foreign currency bought by one USD. Therefore, positive returns represent USD is more valued compared to the other currency, and vice-versa.
from gingado.utils import load_SDMX_datadf = load_SDMX_data(
sources={'BIS': 'WS_XRU_D'},
keys={
'FREQ': 'D',
'CURRENCY': ['BRL', 'CAD', 'CHF', 'EUR', 'GBP', 'JPY', 'MXN'],
'REF_AREA': ['BR', 'CA', 'CH', 'XM', 'GB', 'JP', 'MX']
},
params={'startPeriod': 2003}
)Querying data from BIS's dataflow 'WS_XRU' - US dollar exchange rates, m,q,a...
this dataflow does not have data in the desired frequency and time period.
Querying data from BIS's dataflow 'WS_XRU_D' - US dollar exchange rates, daily...The code below simplifies the column names by removing the identification of the SDMX sources, dataflows and keys and replacing it with the usual code for the bilateral exchange rates.
print("Original column names:")
print(df.columns)
df.columns = ['USD' + col.split('_')[9] for col in df.columns]
print("New column names:")
print(df.columns)Original column names:
Index(['BIS__WS_XRU_D_D__BR__BRL__A', 'BIS__WS_XRU_D_D__CA__CAD__A',
'BIS__WS_XRU_D_D__CH__CHF__A', 'BIS__WS_XRU_D_D__GB__GBP__A',
'BIS__WS_XRU_D_D__JP__JPY__A', 'BIS__WS_XRU_D_D__MX__MXN__A',
'BIS__WS_XRU_D_D__XM__EUR__A'],
dtype='object')
New column names:
Index(['USDBRL', 'USDCAD', 'USDCHF', 'USDGBP', 'USDJPY', 'USDMXN', 'USDEUR'], dtype='object')The dataset looks like this so far (most recent 5 rows displayed only):
df.tail()| USDBRL | USDCAD | USDCHF | USDGBP | USDJPY | USDMXN | USDEUR | |
|---|---|---|---|---|---|---|---|
| TIME_PERIOD | |||||||
| 2022-09-13 | 5.087371 | 1.297297 | 0.950270 | 0.853002 | 142.014742 | 19.814742 | 0.982801 |
| 2022-09-14 | 5.187888 | 1.319019 | 0.962162 | 0.865846 | 143.223223 | 20.048048 | 1.001001 |
| 2022-09-15 | 5.187850 | 1.318255 | 0.957966 | 0.870036 | 143.544836 | 20.018114 | 1.000801 |
| 2022-09-16 | 5.252059 | 1.328712 | 0.962327 | 0.878039 | 143.188668 | 20.095238 | 1.004621 |
| 2022-09-19 | 5.293894 | 1.330731 | 0.966767 | 0.878729 | 143.563564 | 20.133133 | 1.001001 |
We are interested in the percentage change from the previous day.
FX_rate_changes = df.pct_change()
FX_rate_changes.dropna(inplace=True)FX_rate_changes.plot(subplots=True, layout=(4, 2), figsize=(15, 15), sharex=True, title='Selected daily FX rate changes')array([[<AxesSubplot:xlabel='TIME_PERIOD'>,
<AxesSubplot:xlabel='TIME_PERIOD'>],
[<AxesSubplot:xlabel='TIME_PERIOD'>,
<AxesSubplot:xlabel='TIME_PERIOD'>],
[<AxesSubplot:xlabel='TIME_PERIOD'>,
<AxesSubplot:xlabel='TIME_PERIOD'>],
[<AxesSubplot:xlabel='TIME_PERIOD'>,
<AxesSubplot:xlabel='TIME_PERIOD'>]], dtype=object)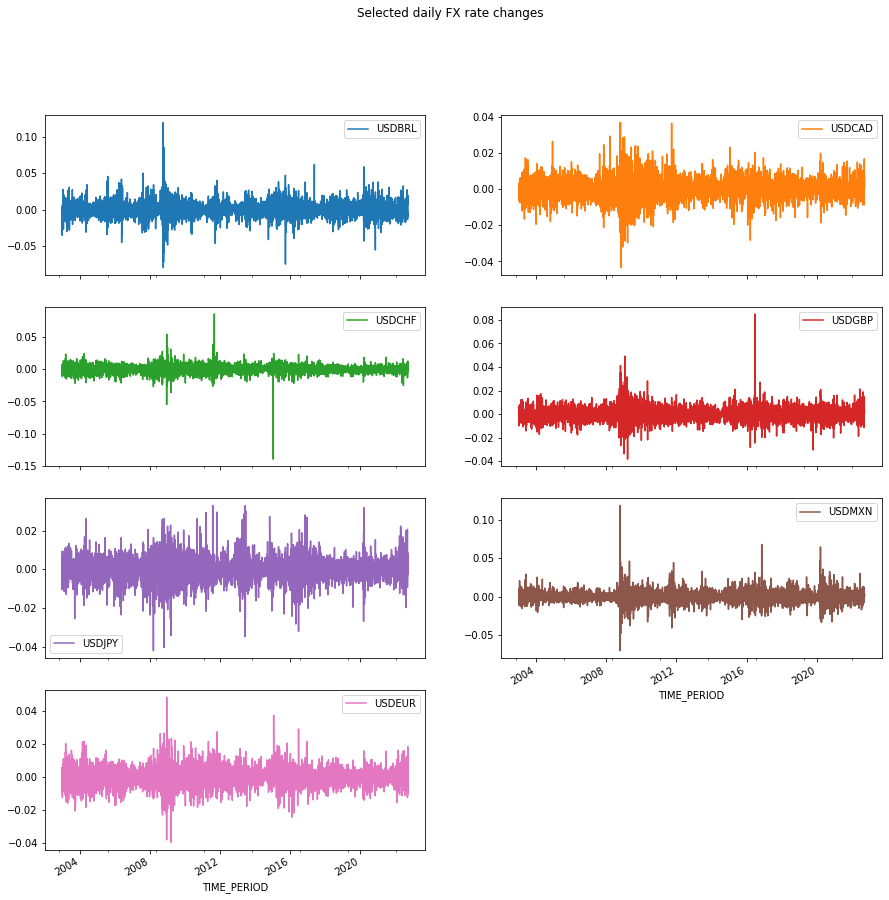
We will complement the FX rates data with two other datasets:
daily central bank policy rates from the Bank for International Settlements (BIS) (2017), and
the daily Composite Indicator of Systemic Stress (CISS), created by Hollo, Kremer, and Lo Duca (2012) and updated by the European Central Bank (ECB).
from gingado.augmentation import AugmentSDMXX = AugmentSDMX(sources={'BIS': 'WS_CBPOL_D', 'ECB': 'CISS'}).fit_transform(FX_rate_changes)Querying data from BIS's dataflow 'WS_CBPOL_D' - Policy rates daily...
Querying data from ECB's dataflow 'CISS' - Composite Indicator of Systemic Stress...2022-09-24 00:51:08,339 pandasdmx.reader.sdmxml - INFO: Use supplied dsd=… argument for non–structure-specific messageit is acceptable in gingado to pass the variable of interest (the “y”, or in this case, FX_rate_changes) as the X argument in fit_transform. This is because this series will also be merged with the additional, augmented data and subsequently lagged along with it.
You can see below that the column names for the newly added columns reflect the source (BIS or ECB), the dataflow (separated from the source by a double underline), and then the specific keys to the series, which are specific to each dataflow.
X.columnsIndex(['USDBRL', 'USDCAD', 'USDCHF', 'USDGBP', 'USDJPY', 'USDMXN', 'USDEUR',
'BIS__WS_CBPOL_D_D__AR', 'BIS__WS_CBPOL_D_D__AU',
'BIS__WS_CBPOL_D_D__BR', 'BIS__WS_CBPOL_D_D__CA',
'BIS__WS_CBPOL_D_D__CH', 'BIS__WS_CBPOL_D_D__CL',
'BIS__WS_CBPOL_D_D__CN', 'BIS__WS_CBPOL_D_D__CO',
'BIS__WS_CBPOL_D_D__CZ', 'BIS__WS_CBPOL_D_D__DK',
'BIS__WS_CBPOL_D_D__GB', 'BIS__WS_CBPOL_D_D__HK',
'BIS__WS_CBPOL_D_D__HR', 'BIS__WS_CBPOL_D_D__HU',
'BIS__WS_CBPOL_D_D__ID', 'BIS__WS_CBPOL_D_D__IL',
'BIS__WS_CBPOL_D_D__IN', 'BIS__WS_CBPOL_D_D__IS',
'BIS__WS_CBPOL_D_D__JP', 'BIS__WS_CBPOL_D_D__KR',
'BIS__WS_CBPOL_D_D__MK', 'BIS__WS_CBPOL_D_D__MX',
'BIS__WS_CBPOL_D_D__MY', 'BIS__WS_CBPOL_D_D__NO',
'BIS__WS_CBPOL_D_D__NZ', 'BIS__WS_CBPOL_D_D__PE',
'BIS__WS_CBPOL_D_D__PH', 'BIS__WS_CBPOL_D_D__PL',
'BIS__WS_CBPOL_D_D__RO', 'BIS__WS_CBPOL_D_D__RS',
'BIS__WS_CBPOL_D_D__RU', 'BIS__WS_CBPOL_D_D__SA',
'BIS__WS_CBPOL_D_D__SE', 'BIS__WS_CBPOL_D_D__TH',
'BIS__WS_CBPOL_D_D__TR', 'BIS__WS_CBPOL_D_D__US',
'BIS__WS_CBPOL_D_D__XM', 'BIS__WS_CBPOL_D_D__ZA',
'ECB__CISS_D__AT__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__BE__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__CN__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__DE__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__ES__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__FI__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__FR__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__GB__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__IE__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__IT__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__NL__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__PT__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_BM__CON',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_CI__IDX',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_CIN__IDX',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_CO__CON',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_EM__CON',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_FI__CON',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_FX__CON',
'ECB__CISS_D__U2__Z0Z__4F__EC__SS_MM__CON',
'ECB__CISS_D__US__Z0Z__4F__EC__SS_CI__IDX',
'ECB__CISS_D__US__Z0Z__4F__EC__SS_CIN__IDX'],
dtype='object')Before proceeding, we also include a differentiated version of the central bank policy data. It will be sparse, since these changes occur infrequently for most central banks, but it can help the model uncover how FX rate changes respond to central bank policy changes.
import pandas as pdX_diff = X.loc[:, X.columns.str.contains("BIS__WS_CBPOL_D", case=False)].diff()
X_diff.columns = [col + "_diff" for col in X_diff.columns]
X = pd.concat([X, X_diff], axis=1)This is how the data looks like now. Note that the names of the added columns reflect the source, dataflow and keys, all separated by underlines (the source is separated from the dataflow by two underlines at all cases). For example, the last key is the jurisdiction of the central bank.
We will keep all the newly added variables - even those that are from countries not in the currency list. This is because the model may uncover any relationship of interest between central bank policies from other countries and each particular currency pair.
X.describe().transpose()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| USDBRL | 5098.0 | 0.000136 | 0.010597 | -0.080226 | -0.005774 | -0.000018 | 0.005402 | 0.120503 |
| USDCAD | 5098.0 | -0.000016 | 0.005844 | -0.043367 | -0.003222 | -0.000138 | 0.003036 | 0.036864 |
| USDCHF | 5098.0 | -0.000050 | 0.006434 | -0.139149 | -0.003241 | 0.000000 | 0.003257 | 0.085326 |
| USDGBP | 5098.0 | 0.000085 | 0.005998 | -0.038140 | -0.003307 | 0.000000 | 0.003241 | 0.085019 |
| USDJPY | 5098.0 | 0.000054 | 0.005970 | -0.041963 | -0.003007 | 0.000116 | 0.003183 | 0.032901 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| BIS__WS_CBPOL_D_D__TH_diff | 5097.0 | -0.000196 | 0.033590 | -1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 |
| BIS__WS_CBPOL_D_D__TR_diff | 5097.0 | -0.006082 | 0.252368 | -4.250000 | 0.000000 | 0.000000 | 0.000000 | 8.500000 |
| BIS__WS_CBPOL_D_D__US_diff | 5097.0 | 0.000221 | 0.038721 | -1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.750000 |
| BIS__WS_CBPOL_D_D__XM_diff | 5097.0 | -0.000294 | 0.027431 | -0.750000 | 0.000000 | 0.000000 | 0.000000 | 0.750000 |
| BIS__WS_CBPOL_D_D__ZA_diff | 5097.0 | -0.001570 | 0.062037 | -1.500000 | 0.000000 | 0.000000 | 0.000000 | 0.750000 |
105 rows × 8 columns
The policy rates for some central banks have less observations than the others, as seen above.
Because some data are missing, we will impute data for the missing dates, by simply propagating the last valid observation, and when that is not possible, replacing the missing information with a “0”.
X.fillna(method='pad', inplace=True)
X.fillna(value=0, inplace=True)Now is a good time to start the model documentation. For this, we can use the standard model card that already comes with gingado.
The goal is to facilitate economists who want to make model documentation a part of their normal workflow.
from gingado.model_documentation import ModelCardmodel_doc = ModelCard()
model_doc.open_questions()['model_details__developer',
'model_details__version',
'model_details__type',
'model_details__info',
'model_details__paper',
'model_details__citation',
'model_details__license',
'model_details__contact',
'intended_use__primary_uses',
'intended_use__primary_users',
'intended_use__out_of_scope',
'factors__relevant',
'factors__evaluation',
'metrics__performance_measures',
'metrics__thresholds',
'metrics__variation_approaches',
'evaluation_data__datasets',
'evaluation_data__motivation',
'evaluation_data__preprocessing',
'training_data__training_data',
'quant_analyses__unitary',
'quant_analyses__intersectional',
'ethical_considerations__sensitive_data',
'ethical_considerations__human_life',
'ethical_considerations__mitigations',
'ethical_considerations__risks_and_harms',
'ethical_considerations__use_cases',
'ethical_considerations__additional_information',
'caveats_recommendations__caveats',
'caveats_recommendations__recommendations']As an example, we can add the following information to the model:
model_doc.fill_info({
'intended_use': {
'primary_uses': 'These models are simplified toy models made to illustrate the use of gingado',
'out_of_scope': 'These models were not constructed for decision-making and as such their use as predictors in real life decisions is strongly discouraged and out of scope.'
},
'metrics': {
'performance_measures': 'Consistent with most papers reviewed by Rossi (2013), these models were evaluated by their root mean squared error.'
},
'ethical_considerations': {
'sensitive_data': 'These models were not trained with sensitive data.',
'human_life': 'The models do not involve the collection or use of individual-level data, and have no foreseen impact on human life.'
},
})This model will not include any contemporaneous variable. Therefore, all regresors must be lagged.
For illustration purposes, we use 5 lags in this exercise.
from gingado.utils import Lagn_lags = 5
X_lagged = Lag(lags=n_lags).fit_transform(X)
X_lagged
y = FX_rate_changes[n_lags:]Now is a good opportunity to check by how much we have increased our regressor space:
pd.Series({
"FX rates only": y.shape[1],
"... with augmentation_": X.shape[1],
"... lagged": X_lagged.shape[1]
})FX rates only 7
... with augmentation_ 105
... lagged 525
dtype: int64Our dataset is now complete. Before using it to train the models, we hold out the most recent data to serve as our testing dataset, so we can compare our models with real out-of-sample information.
We can choose, say, 1st January 2022.
cutoff = '2020-01-01'
X_train, X_test = X_lagged[:cutoff], X_lagged[cutoff:]
y_train, y_test = y[:cutoff], y[cutoff:]model_doc.fill_info({
'training_data':
{'training_data':
"""
The training data comprise time series obtained from official sources (BIS and ECB) on:
* foreign exchange rates
* central bank policy rates
* an estimated indicator for systemic stress
The training and evaluation datasets are the same time series, only different windows in time."""
}
})The current status of the documentation is:
pd.Series(model_doc.show_json())model_details {'developer': 'Person or organisation developi...
intended_use {'primary_uses': 'These models are simplified ...
factors {'relevant': 'Relevant factors', 'evaluation':...
metrics {'performance_measures': 'Consistent with most...
evaluation_data {'datasets': 'Datasets', 'motivation': 'Motiva...
training_data {'training_data': '
The training data ...
quant_analyses {'unitary': 'Unitary results', 'intersectional...
ethical_considerations {'sensitive_data': 'These models were not trai...
caveats_recommendations {'caveats': 'For example, did the results sugg...
dtype: objectRossi (2013) highlights that few predictors beat the random walk without drift model. This is a good opportunity to showcase how we can use gingado’s in-built base class ggdBenchmark to build our customised benchmark model, in this case a random walk.
The calculation of the random walk benchmark is very simple. Still, creating a gingado benchmark offers some advantages: it is easier to compare alternative models, and the model documentation is done more seamlessly.
A custom benchmark model must implement the following steps:
sub-class ggdBenchmark (or alternatively implement its methods)
define an estimator that is compatible with scikit-learn’s API:
fit method that returns selfIf the user is relying on a custom estimator - like in this case, a random walk estimator to align with the literature - then this custom estimator also has some requirements:
it should ideally subclass scikit-learn’s BaseEstimator (mostly for the get_params / set_params methods)
three methods are necessary:
fit, which should at least create an attribute ending in an underline (“_“), so that gingado knows it is fittedpredictscoreimport numpy as np
from gingado.benchmark import ggdBenchmark
from sklearn.base import BaseEstimator
from sklearn.ensemble import VotingRegressor
from sklearn.model_selection import TimeSeriesSplitclass RandomWalkEstimator(BaseEstimator):
def __init__(self, scoring='neg_root_mean_squared_error'):
self.scoring = scoring
def fit(self, X, y=None):
self.n_samples_ = X.shape[0]
return self
def predict(self, X):
return np.zeros(X.shape[0])
def score(self, X, y, sample_weight=None):
from sklearn.metrics import mean_squared_error
y_pred = self.predict(X)
return mean_squared_error(y, y_pred, sample_weight=sample_weight, squared=False)
def forecast(self, forecast_horizon=1):
self.forecast_horizon = forecast_horizon
return np.zeros(self.forecast_horizon)
class RandomWalkBenchmark(ggdBenchmark):
def __init__(
self,
estimator=RandomWalkEstimator(),
auto_document=ModelCard,
cv=TimeSeriesSplit(n_splits=10, test_size=60),
ensemble_method=VotingRegressor,
verbose_grid=None):
self.estimator=estimator
self.auto_document=auto_document
self.cv=cv
self.ensemble_method=ensemble_method
self.verbose_grid=verbose_grid
def fit(self, X, y=None):
self.benchmark=self.estimator
self.benchmark.fit(X, y)
return selfNow that we have a benchmark, we can create candidate models that will try to beat it.
In this simplified example, we will choose only two: a random forest, an AdaBoost regressor and a Lasso model. Their hyperparameters are not particularly important for the example, but of course they could be fine-tuned as well.
In the language of Rossi (2013), the models below are one “single-equation, lagged fundamental model” for each currency.
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.linear_model import Lassoforest = RandomForestRegressor(n_estimators=250, max_features='log2').fit(X_train, y_train['USDBRL'])
adaboost = AdaBoostRegressor(n_estimators=150).fit(X_train, y_train['USDBRL'])
lasso = Lasso(alpha=0.1).fit(X_train, y_train['USDBRL'])
rw = RandomWalkBenchmark().fit(X_train, y_train['USDBRL'])We can now compare the model results, using the test dataset we held out previously.
Note that we must pass the criterion against which we are comparing the forecasts.
from sklearn.metrics import mean_squared_errorresults = rw.compare_fitted_candidates(
X_test, y_test['USDBRL'],
candidates=[forest, adaboost, lasso],
scoring_func=mean_squared_error)
pd.Series(results)RandomWalkEstimator() 0.000127
RandomForestRegressor(max_features='log2', n_estimators=250) 0.000129
AdaBoostRegressor(n_estimators=150) 0.000132
Lasso(alpha=0.1) 0.000126
dtype: float64As mentioned above, benchmarks can facilitate the model documentation. In addition to the broader documentation that is already ongoing, each benchmark object create their own where they store model information. We can use that for the broader documentation.
In our case, the only parameter we created above during fit is the number of samples: not a particularly informative variable but it was included just for illustration purposes. In any case, the parameter appears in the “model_details” section, item “info”, of the benchmark’s rw documentation. Similarly, the parameters of more fully-fledged estimators also appear in that section.
rw.document()
rw.model_documentation.show_json()['model_details']['info']{'n_samples_': 4394}model_doc.fill_info({
'model_details': {'info': rw.model_documentation.show_json()['model_details']['info']}
})model_doc.show_json(){'model_details': {'developer': 'Person or organisation developing the model',
'datetime': '2022-09-24 00:51:37 ',
'version': 'Model version',
'type': 'Model type',
'info': {'n_samples_': 4394},
'paper': 'Paper or other resource for more information',
'citation': 'Citation details',
'license': 'License',
'contact': 'Where to send questions or comments about the model'},
'intended_use': {'primary_uses': 'These models are simplified toy models made to illustrate the use of gingado',
'primary_users': 'Primary intended users',
'out_of_scope': 'These models were not constructed for decision-making and as such their use as predictors in real life decisions is strongly discouraged and out of scope.'},
'factors': {'relevant': 'Relevant factors',
'evaluation': 'Evaluation factors'},
'metrics': {'performance_measures': 'Consistent with most papers reviewed by Rossi (2013), these models were evaluated by their root mean squared error.',
'thresholds': 'Decision thresholds',
'variation_approaches': 'Variation approaches'},
'evaluation_data': {'datasets': 'Datasets',
'motivation': 'Motivation',
'preprocessing': 'Preprocessing'},
'training_data': {'training_data': '\n The training data comprise time series obtained from official sources (BIS and ECB) on:\n * foreign exchange rates\n * central bank policy rates\n * an estimated indicator for systemic stress\n The training and evaluation datasets are the same time series, only different windows in time.'},
'quant_analyses': {'unitary': 'Unitary results',
'intersectional': 'Intersectional results'},
'ethical_considerations': {'sensitive_data': 'These models were not trained with sensitive data.',
'human_life': 'The models do not involve the collection or use of individual-level data, and have no foreseen impact on human life.',
'mitigations': 'What risk mitigation strategies were used during model development?',
'risks_and_harms': '\n What risks may be present in model usage? Try to identify the potential recipients, likelihood, and magnitude of harms. \n If these cannot be determined, note that they were consid- ered but remain unknown',
'use_cases': 'Are there any known model use cases that are especially fraught?',
'additional_information': '\n If possible, this section should also include any additional ethical considerations that went into model development, \n for example, review by an external board, or testing with a specific community.'},
'caveats_recommendations': {'caveats': 'For example, did the results suggest any further testing? Were there any relevant groups that were not represented in the evaluation dataset?',
'recommendations': 'Are there additional recommendations for model use? What are the ideal characteristics of an evaluation dataset for this model?'}}We can save the documentation to disk in JSON format with model_doc.save_json(), or parse it to create other documents (eg, a PDF file) using third-party libraries.