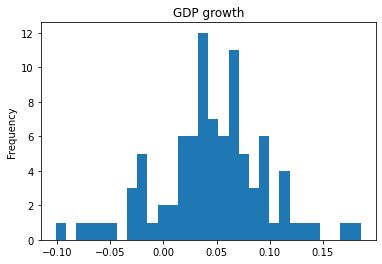
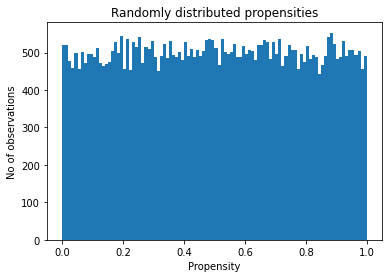
Dataset used in R Barro and J-W Lee’s Sources of Economic Growth (1994)
Type
Default
Details
return_tuple
bool
True
Whether to return the data in a tuple or jointly in a single pandas DataFrame
Robert Barro and Jong-Wha Lee’s (1994) dataset has been used over time by other economists, such as by Belloni, Chernozhukov, and Hansen (2011) and Giannone, Lenza, and Primiceri (2021). This function uses the version available in their online annex. In that paper, this dataset corresponds to what the authors call “macro2”.
The original data, along with more information on the variables, can be found in this NBER website. A very helpful codebook is found in this repo.
Simulated dataset with causal effects from treatment
Type
Default
Details
n_samples
int
100
Number of observations
n_features
int
100
Number of covariates
pretreatment_outcome
function
Function that generates the outcome variable before any treatment effects
treatment_propensity
function
Number between 0 and 1, or function that generates a treatment propensity for each observation
treatment_assignment
function
Function that controls how treatment propensities actually result in observations being treated
treatment
function
Function that determines the magnitude of the treatment for each observation, conditional on assignment
treatment_effect
function
Function that calculates the effect of a treatment to each treated observation
bias
float
0
The value of the constant
noise
float
0
If 0, the pretreatment value of the overview does not include a random term. If > 0, a random draw of the normal distribution with scale noise is drawn
random_state
NoneType
None
Seed for the random number generator
return_propensity
bool
False
Whether the treatment propensity of each observation is to be retuned
return_assignment
bool
False
Whether the treatment assignment status of each observation is to be retuned
return_treatment_value
bool
False
Whether the treatment value of each observation is to be retuned
return_treatment_effect
bool
True
Whether the treatment effect of each observation is to be retuned
return_pretreatment_y
bool
False
Whether the outcome variable of each observation before the inclusion of treatment effects is to be retuned
return_as_dict
bool
False
Whether the results are returned as a list (False) or as a dictionary (True)
make_causal_effect creates a dataset for when the question of interest is related to the causal effects of a treatment. For example, for a simulated dataset, we can check that \(Y_i\) corresponds to the sum of the treatment effects plus the component that does not depend on the treatment:
The pre-treatment outcome \(Y_i|X_i\) (the part of the outcome variable that is not dependent on the treatment) might be defined by the user. This corresponds to the value of the outcome for any untreated observations. The function should always take at least two arguments: X and bias, even if one of them is unused; bias is the constant. The argument is zero by default but can be set by the user to be another value.
And of course, the outcome might also have a random component.
In these cases (and in other parts of this function), when the user wants to use the same random number generator as the other parts of the function, the function must have an argment rng for the NumPy random number generator used in other parts of the function.
The propensity can also be randomly allocated, together with covariate dependence or not. Note that even if the propensity is completely random and does not depend on covariates, the function must still use the argument X to calculate a random vector with the appropriate size.
As seen above, every observation has a given treatment propensity - the chance that they are treated. Users can define how this propensity translates into actual treatment with the argument treatment_assignment. This argument takes a function, which must have an argument called propensity.
The default value for this argument is a function returning 1s with probability propensity and 0s otherwise. Any other function should always return either 0s or 1s for the data simulator to work as expected.
While the case above is likely to be the most useful in practice, this argument accepts more complex relationships between an observation’s propensity and the actual treatment assignment.
For example, if treatment is subject to rationing, then one could simulate data with 10 observations where only the samples with the highest (say, 3) propensity scores get treated, as below:
The treatment argument indicates the magnitude of the treatment for each observation assigned for treatment. Its value is always a function that must have an argument called assignment, as in the first example below.
In the simplest case, the treatment is a binary variable indicating whether or not a variable was treated. In other words, the treatment is the same as the assignment, as in the default value.
But users can also simulate data with heterogenous treatment, conditional on assignment. This is done by including a pararemeter X in the function, as shown in the second example below.
Heterogenous treatments may occur in settings where treatment intensity, conditional on assignment, varies across observations. Please note the following:
the heterogenous treatment amount may or may not depend on covariates, but either way, if treatment values are heterogenous, then X needs to be an argument of the function passed to treatment, if nothing else to make sure the shapes match; and
if treatments are heterogenous, then it is important to multiply the treatment value with the assignment argument to ensure that observations that are not assigned to be treated are indeed not treated (the function will return an AssertionError otherwise).
In contrast to the function above, in the chunk below the function make_causal_effect fails because a treatment value is also assigned to observations that were not assigned for treatment.
The treatment effect can be homogenous, ie, is doesn’t depend on any other characteristic of the individual observations (in other words, does not depend on \(X_i\)), or heterogenous (where the treatment effect on \(Y_i\) does depend on each observation’s \(X_i\)). This can be done by specifying the causal relationship through a lambda function, as below:
Barro, Robert J., and Jong-Wha Lee. 1994. “Sources of Economic Growth.”Carnegie-Rochester Conference Series on Public Policy 40: 1–46. https://doi.org/10.1016/0167-2231(94)90002-7.
Belloni, Alexandre, Victor Chernozhukov, and Christian Hansen. 2011. “Inference for High-Dimensional Sparse Econometric Models.”arXiv Preprint arXiv:1201.0220.
Giannone, Domenico, Michele Lenza, and Giorgio E Primiceri. 2021. “Economic Predictions with Big Data: The Illusion of Sparsity.”Econometrica 89 (5): 2409–37.